Хороший и качественный датасет — один из самых ценных компонентов, необходимых для машинного обучения. Эффективность такого обучения напрямую зависит от достаточного количества данных. Соответственно, чем больше данных, тем эффективнее будет работа с искусственным интеллектом. К сожалению, для многих реальных задач получить хороший датасет довольно дорого.
Один из выходов из этой ситуации – это использование открытых данных, которые можно найти в интернете. Обычно такие данные предоставляют различные сообщества open-source и некоторые крупные компании. С каждым годом объём общедоступных данных растёт, и такие датасеты вполне подходят для решения определённых задач.
Мы также используем в своей работе общедоступные данные. Поэтому решили собрать на портале различные датасеты из открытых источников. С нашей коллекцией, которая постоянно пополняется, вы можете ознакомиться в соответствующем разделе. Каждый датасет содержит ссылку на источник и подробное описание.

Общедоступный многоязычный корпус для перевода речи. Он охватывает восемь языковых направлений, от английского до немецкого, испанского, французского, итальянского, голландского, португальского, ...
Далее
Набор содержит 200 000 часов данных распознавания речи, записанных с помощью различного профессионального оборудования, охватывающих самые разные сцены. В записи ...
Далее
Бесплатный набор данных, состоящий из 21 024 собранных на основе краудсорсинга записей смеха, вздохов, кашля, откашливания, чихания и фырканья от ...
Далее
Каждая запись в наборе данных состоит из уникального файла MP3 и соответствующего текстового файла. Многие из 20 217 записанных часов ...
Далее
Качественный датасет состоит из 1500 русских вопросов разной сложности, их английских машинных переводов, SPARQL-запросов к Викиданным, справочных ответов, а также ...
Далее
Набор содержит 4601 электронное письмо, помеченное как спам и не спам. Получить более подробную информацию о проекте, а также скачать ...
Далее
Набор содержит более 15 000 твитов об авиакомпаниях. Данные Twitter были извлечены с февраля 2015 года, и участников попросили сначала классифицировать ...
Далее
Набор данных состоит примерно из 20 000 документов, разделенных равномерно по 20 различным группам новостей. Коллекция стала популярным набором данных ...
Далее
Яндекс разработал и опубликовал крупнейший датасет для обучения беспилотных автомобилей прогнозированию движений других машин и пешеходов. Он содержит в себе данные, эквивалентные 69 дням непрерывной ...
Далее
Набор данных изображений для методов обнаружения аномалий с упором на промышленный контроль. Поднабор данных каждой категории состоит из обучающего набора изображений ...
Далее
Крупномасштабный набор данных, ориентированный на семантическое понимание городских уличных сцен. Он предоставляет семантические, экземплярные и плотные пиксельные аннотации для 30 классов, ...
Далее
Высококачественный набор изображений человеческих лиц, изначально созданный в качестве эталона для генеративно-состязательных сетей (GAN). Набор данных состоит из 70 000 ...
Далее
Один из крупнейших общедоступных наборов данных изображений с высоты птичьего полета. Он содержит изображения сложных сцен со всего мира, аннотированные с ...
Далее
Впервые для русского языка с нуля был разработан бенчмарк из девяти заданий, собранных и организованных по аналогии с методикой SuperGLUE. По ...
Далее
Набор аудиоданных, содержащий более 100 000 высказываний 1251 знаменитости, извлеченных из видео, загруженных на YouTube. Получить более подробную информацию о ...
Далее
Это набор данных для распознавания действий, состоящий из реалистичных видеороликов с действиями, собранных с YouTube и имеющих 101 категорию действий ...
Далее
Концептуальные подписи — это набор данных, содержащий пары (URL-адрес изображения, подпись), предназначенные для обучения и оценки машинно-обучаемых систем подписей к ...
Далее
Эти вопросы возникают естественным образом — они генерируются без подсказок и без каких-либо ограничений. Каждый пример представляет собой триплет (вопрос, ...
Далее
Этот набор данных подходит для моделей обучения обнаружению голосовой активности (VAD) и различению музыки и речи. Набор данных состоит из музыки ...
Далее
Датасет Hyperism от команды машинного обучения Apple с 77,4 тыс. изображениями 461 сцены внутри помещений для обучения ИИ-алгоритмов. Набор данных ...
Далее
Набор данных IBM Project CodeNet с 14 млн образцами программного кода для обучения ИИ решению задач в области программирования. Цель ...
Далее
Набор данных в основном состоит из записанных аудиофайлов, аннотированных вручную на краудсорсинговой платформе. Общая продолжительность аудио составляет около 1240 часов ...
Далее
Данные собраны из примерно 1000 часов чтения английской речи с частотой 16 кГц. Данные получены из прочитанных аудиокниг из проекта LibriVox ...
Далее
Возможность распознавать атрибуты пешеходов, такие как пол и стиль одежды на большом расстоянии представляет практический интерес в сценариях наблюдения вдали, ...
Далее
Это набор данных для двоичной классификации тональности. Состоит из 25 000 крайне полярных обзоров фильмов для обучения и 25 000 для ...
Далее
Набор данных содержит 167140 изображений логотипов из 10 категорий: еда, одежда, транспорт и другие. Получить более подробную информацию о проекте, ...
Далее
Набор данных из 4372 изображений и 1,51 миллиона аннотаций. Предлагаемый набор данных собирается при различных сценариях и условиях окружающей среды . Кроме того, набор данных предоставляет ...
Далее
Данный набор состоит из 2,7 миллионов новостных статей и эссе из 27 американских изданий. Включает дату, заголовок, публикацию, текст статьи, название ...
Далее
Данный набор предназначен для крупномасштабного, долгосрочного и многообъектного визуального анализа. Он состоит из 555 статических изображений (390 для обучения, 165 ...
Далее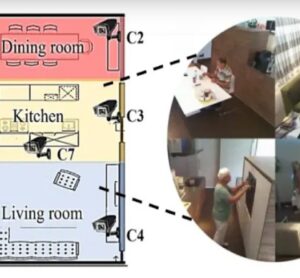
Эти данные были записаны в квартире, оборудованной 7 камерами. Набор содержит 31 повседневную деятельность и 18 предметов. Испытуемые - пожилые ...
Далее
Основное требование для создания интеллектуальных систем помощи водителю и самостоятельного вождения - это качественное восприятие текста, который встречается на проезжей ...
Далее
Представленный набор данных с открытым исходным кодом позволяет изучать сложные городские дорожные ситуации, используя полный комплект датчиков настоящего беспилотного автомобиля ...
Далее
Набор данных COVID-CT-Dataset содержит 349 изображений со снимками компьютерной томографии лёгких, содержащих клинические данные о COVID-19 от 216 пациентов. В ...
Далее
