
Во многих своих статьях мы говорим, что для обучения искусственного интеллекта необходимы огромные объемы качественных данных. В этом предложении есть два ключевых слова – огромные объемы и качественные данные. Давайте обсудим оба по отдельности.
Сбор данных
Само по себе получение больших объемов данных – гигантская задача. Существуют различные методы сбора данных. Это могут быть внутренние источники, такие как CRM, аналитические таблицы, списки потенциальных клиентов и многое другое. Также есть бесплатные внешние источники: правительственные веб-сайты, наборы данных в открытых источниках и многое другое.
Кроме того, есть возможность получения данных путем извлечения их со страниц веб-ресурсов. Если все, что упомянуто, звучит сложно, вы всегда можете заказать данные у сторонних организаций.
Качество данных
Независимо от источника данные будут хаотичными и неорганизованными (за исключением данных от сторонних компаний). Могут быть недостающие значения, нерелевантная информация, устаревшие данные и многое другое. Этот набор данных нельзя использовать для обучения искусственного интеллекта, потому что это приведёт к неточным результатам.
Вот почему данные необходимо очистить, а затем разметить. Чтобы машины могли понять, что это за данные. Это, опять же, может сделать собственная команда или можно передать на аутсорсинг. Самостоятельная разметка потребует увеличения рабочего времени. С другой стороны, аутсорсинг иногда может оказаться дорогостоящим в зависимости от типа данных. Вот почему существует ряд удобных альтернативных решений, которые называют автоматизированной разметкой.
Это когда машина берет на себя ответственность за разметку и передает её результат на обучение искусственного интеллекта. Все, что нужно сделать людям, – это придумать алгоритмы, которые могли бы научить машины идентифицировать и размечать необходимые элементы.
3 метода автоматической маркировки в машинном обучении
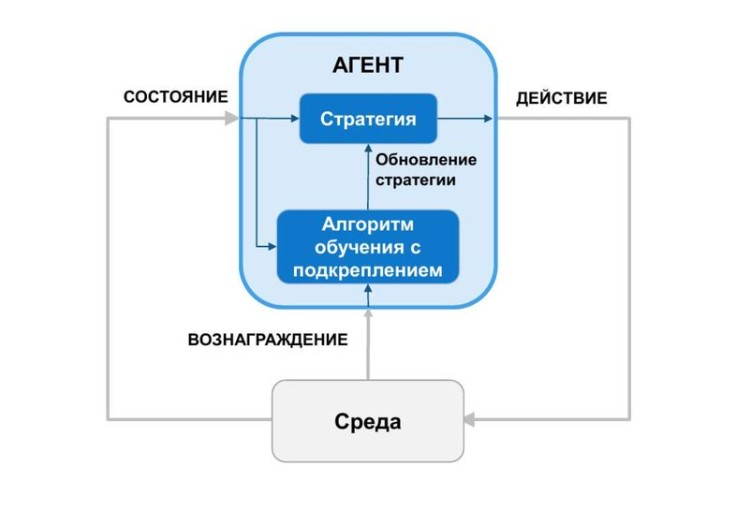
Обучение с подкреплением
Этот метод основан на том принципе, что действующий алгоритм будет поощряться за свои положительные результаты и наказываться за отрицательные. Со временем он естественным образом усваивает концепцию, адаптируется и учится давать точные результаты. Применяя метод проб и ошибок, он начинает прогнозировать результаты, которые соответствуют контексту, которому он обучил себя с помощью собственной обратной связи.
Проблемы в регрессии и классификации выявляются и устраняются автономно, благодаря его способности адаптироваться к изменяющимся результатам на основе циклов обратной связи. Например, когда алгоритм узнает, что на представленном изображении изображена кошка, а не собака, он учится различать собак и продолжает совершенствоваться. Когда в следующий раз ему показывают свежее изображение кошки, он идентифицирует ее правильно.
Контролируемое обучение
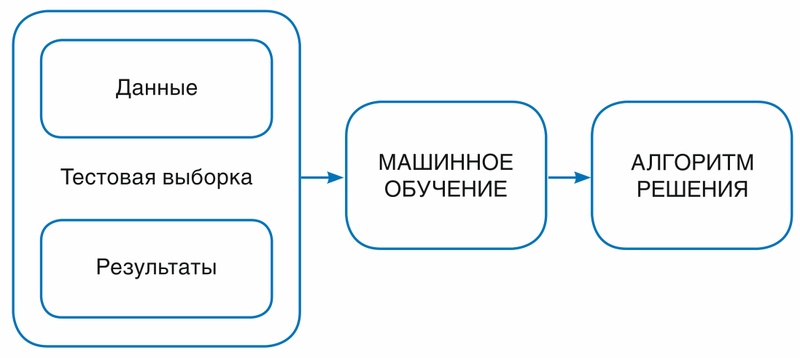
Контролируемое обучение – это метод, при котором алгоритм машинного обучения обучается путем сопоставления входных данных с конкретными выходными данными. Проще говоря, он учится на примерах, которыми его снабжают. Контролируемое обучение очень эффективно в прогностической аналитике, где оно может сопоставлять исторические данные с конкретными прогнозами.
Например, обучение под наблюдением может быть использовано для прогнозирования:
- неисправности оборудования на заводе на основе истории его поломок,
- вероятности того, что человек погасит свой кредит на основе его кредитной истории,
- вероятности того, что водители станут причиной несчастных случаев на основе их истории вождения для расчета страховых взносов
- и многое другое.
Хотя это идеальный метод автоматизации маркировки данных, это само по себе является своего рода иронией, потому что для контролируемого обучения в первую очередь требуются огромные объемы предварительно помеченных данных, чтобы начать процесс обучения. Введение ошибок или неправильно маркированных объектов может исказить результаты, что в конечном итоге сделает процесс бесполезным.
Обучение без учителя
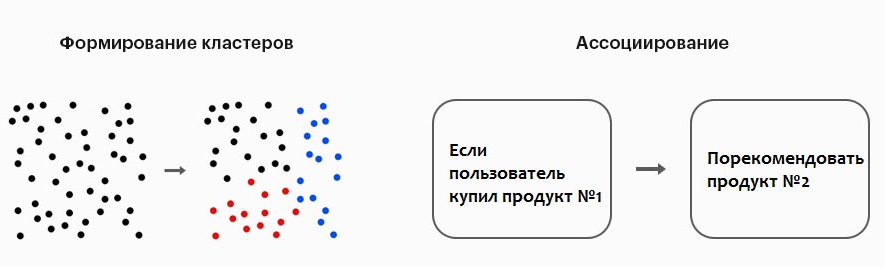
Это полная противоположность обучению под наблюдением. Неконтролируемое обучение процветает на неструктурированных или необработанных данных, где оно разрабатывает свои собственные механизмы для классификации данных по кластерам и извлечения из них смысла. Обучение происходит автономно, без какого-либо ручного вмешательства. Это означает, что ему не нужны наборы данных, помеченные людьми, чтобы понять, кто собака, а кто кошка. Он выясняет это сам по себе.
Подведение итогов
Итак, мы рассмотрели три метода автоматической маркировки данных. Не существует жестких правил, определяющих, какой метод является наиболее эффективным для вашего бизнеса. Все зависит от ваших требований, сегмента рынка, в котором вы работаете, наличия контекстуальных данных, вашего времени выхода на рынок и других важных факторов.