
- Классификация
Классификация текста — это процесс присвоения предопределенных тегов или категорий неструктурированному тексту. Он считается одним из самых полезных методов обработки естественного языка, потому что он настолько универсален и может организовывать, структурировать и классифицировать практически любую форму текста для предоставления значимых данных и решения проблем.

К наиболее распространенным задачам классификации текста можно отнести:
Анализ настроений (мнений)
Выявляет и изучает эмоции в тексте. Использует мощные алгоритмы машинного обучения для автоматического считывания и классификации по полярности мнений (положительные, отрицательные, нейтральные), по чувствам и эмоциям автора, даже по контексту и сарказму.
Тематический анализ
Классифицирует тексты по темам.
Обнаружение намерений
Используется для автоматического понимания причин обратной связи с клиентами. Это жалоба? Или клиент пишет с намерением приобрести продукт? Машинное обучение может читать разговоры чат-ботов или электронные письма и автоматически направлять их соответствующему отделу или сотруднику.
- Извлечение текста
Извлечение текста — еще один широко используемый метод анализа текста, который извлекает фрагменты данных, которые уже существуют в любом заданном тексте. Можно извлекать ключевые слова, цены, названия компаний, спецификации продуктов и т. д.
Извлечение ключевых слов
Ключевые слова — это наиболее часто используемые и наиболее релевантные термины в тексте, слова и фразы, обобщающие содержание текста.
Распознавание объектов
Сущности — это люди, компании или места, упомянутые в тексте.
- Частота слов
Метод анализа текста, который измеряет наиболее часто встречающиеся слова в тексте. Именно так можно определить тему текста и провести анализ настроений. Мы знаем, что слово «интересный» обычно относится к положительным впечатлениям. Так что если вы видите это слово в отзыве, значит, клиент доволен. Однако этот метод не чувствителен к сарказму, который может повлиять на общие результаты анализа.
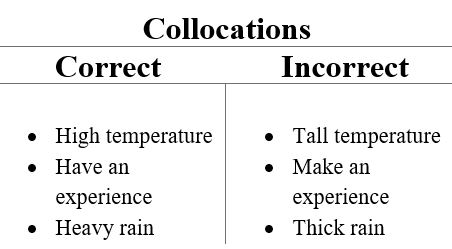
- Коллокация (словосочетание)
Словосочетаниями называются два, три и более слова, которые часто употребляются вместе в речи. Одно и то же слово в разных словосочетаниях может иметь разное значение.
Коллокация может быть полезна для выявления скрытых семантических структур и повышения детализации информации за счет подсчета биграмм и триграмм как одного слова.
- Анализ соответствия
Конкорданс — это таблица, которая отображает разные значения одного и того же слова в разных контекстах. Анализ соответствия и словосочетаний полезен для устранения неоднозначности значений ключевых слов.
- Кластеризация
Текстовые кластеры способны понимать и группировать огромное количество неструктурированных данных. Хотя они менее точны, чем алгоритмы классификации, алгоритмы кластеризации реализуются быстрее, поскольку для обучения моделей не нужно помечать примеры. Это означает, что эти интеллектуальные алгоритмы извлекают информацию и делают прогнозы без использования обучающих данных, иначе называемых неконтролируемым машинным обучением.
Google — отличный пример того, как работает кластеризация. Когда вы ищете термин в Google, задумывались ли вы когда-нибудь о том, что для получения релевантных результатов требуется всего несколько секунд? Алгоритм Google разбивает неструктурированные данные с веб-страниц и группирует страницы в кластеры вокруг набора похожих слов или n-грамм (всех возможных комбинаций соседних слов или букв в тексте). Таким образом, страницы из кластера, которые содержат большее количество слов или n-грамм, релевантных поисковому запросу, будут отображаться первыми в результатах.