
Идентификация говорящего
Это процесс добавления помеченных областей к аудиопотокам и определения временных меток начала и окончания для разных выступающих. По сути, вы разбиваете входной аудиофайл на сегменты и назначаете метки частям с голосами. Часто также отмечаются сегменты с музыкой, фоновым шумом и тишиной.
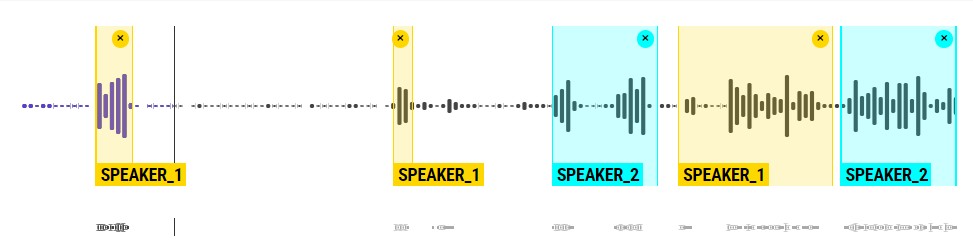
Аудиотранскрипционная аннотация
Аннотирование лингвистических данных в аудиофайлах — более сложный процесс, требующий добавления тегов для всех окружающих звуков и транскрипций для речи в дополнение к лингвистическим регионам. Многие инструменты аудио- и видеоаннотации позволяют пользователям объединять различные входные данные, такие как аудио и текст, в единый простой интерфейс аудиотранскрипции.
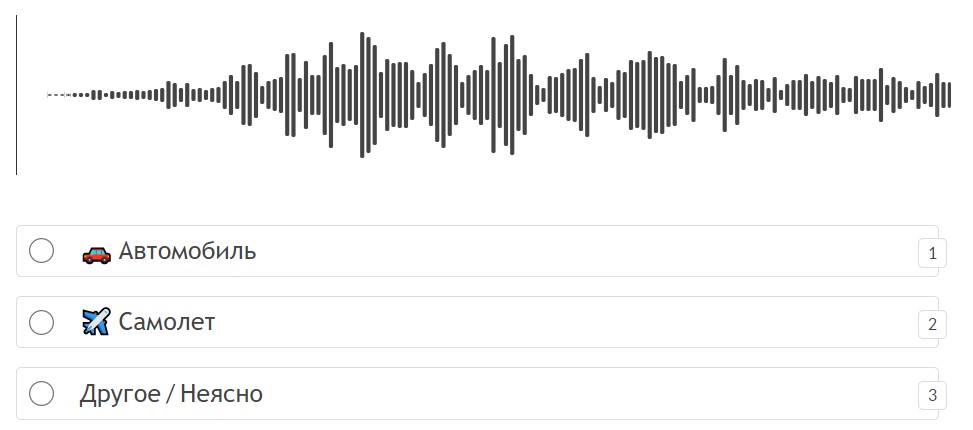
Аудио классификация
Задания по классификации аудио требуют, чтобы люди-аннотаторы прослушивали аудиозаписи и классифицировали их на основе ряда предопределенных категорий. Категории могут описывать количество или тип говорящих, намерения, разговорный язык или диалект, фоновый шум или семантически связанную информацию.
Аннотация звуковых эмоций
Аннотация звуковых эмоций, как следует из названия, направлена на определение чувств говорящего, таких как счастье, печаль, гнев, страх и удивление, и это лишь некоторые из них. Этот процесс является более точным, чем анализ тональности текста, поскольку аудиопотоки предоставляют ряд дополнительных подсказок, таких как интенсивность голоса, высота тона, скачки высоты тона или скорость речи.
Примеры использования маркировки аудио
Поскольку добавление меток к аудиофайлам является краеугольным камнем распознавания речи, оно находит применение в:
- разработка голосовых помощников, таких как Siri и Alexa,
- перевод речи в текст,
- предоставление контекста разговоров для продвинутых чат-ботов,
- измерение удовлетворенности клиентов по звонкам в службу поддержки,
- разработка приложений для изучения языка и оценки произношения.