
Автоматическое распознавание речи, или ASR, — это использование технологии машинного обучения или искусственного интеллекта (ИИ) для преобразования человеческой речи в читаемый текст. За последнее десятилетие эта область значительно расширилась: системы ASR появились в популярных приложениях, которые мы используем каждый день.
Основные области применения ASR
Огромные достижения в области ASR привели к корреляции с ростом API-интерфейсов преобразования речи в текст. Компании используют технологию ASR для приложений преобразования речи в текст в самых разных отраслях. Вот некоторые примеры:
Телефония. Отслеживание вызовов, решения для облачных телефонов и контакт-центры нуждаются в точных транскрипциях, а также в инновационных аналитических функциях, таких как Conversational Intelligence, аналитика вызовов, диаризация говорящих и многое другое.
Платформы для видео: субтитры в режиме реального времени и асинхронные видео являются отраслевым стандартом. Платформы (как и видеоредакторы ) также нуждаются в категоризации контента и модерации контента для улучшения доступности и поиска.
Медиа-мониторинг: API-интерфейсы преобразования речи в текст могут помочь телетрансляциям, подкастам, радио, а также более быстро и точно обнаруживать упоминания брендов и других тем для повышения качества рекламы.
Виртуальные встречи. Платформы для встреч, такие как Zoom, Google Meet, WebEx и другие, нуждаются в точных расшифровках и возможности анализировать этот контент, чтобы получать ключевые идеи и действовать.
Как работает ASR
На сегодняшний день существует два основных подхода к автоматическому распознаванию речи: традиционный гибридный подход и сквозной подход к глубокому обучению.
Традиционный гибридный подход
Традиционный гибридный подход является устаревшим подходом к распознаванию речи и доминировал в этой области в течение последних пятнадцати лет. Многие компании до сих пор полагаются на этот традиционный гибридный подход просто потому, что так всегда делалось — существует больше знаний о том, как построить надежную модель, благодаря обширным доступным данным исследований и обучения, несмотря на плато в точности.
Традиционные системы HMM (скрытые марковские модели) и GMM (модели гауссовых смесей) требуют принудительного выравнивания данных. Принудительное выравнивание — это процесс получения текстовой транскрипции звукового речевого сегмента и определения того, где во времени встречаются определенные слова в речевом сегменте.
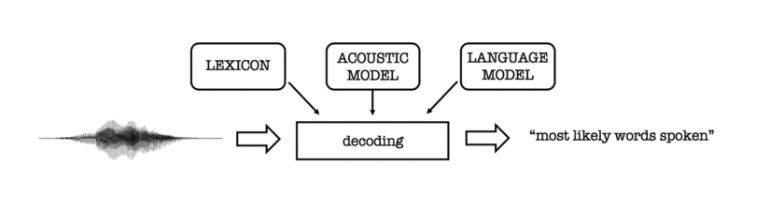
Как вы можете видеть на приведенной выше иллюстрации, этот подход сочетает в себе лексическую модель + акустическую модель + языковую модель для прогнозирования транскрипции.
Модель лексики описывает, как слова произносятся фонетически. Обычно вам нужен собственный набор фонем для каждого языка, созданный опытными фонетиками вручную.
Акустическая модель (АМ) моделирует акустические паттерны речи. Задача акустической модели состоит в том, чтобы предсказать, какой звук или фонема произносится в каждом сегменте речи, на основе принудительно выровненных данных. Акустическая модель обычно представляет собой вариант HMM или GMM.
Языковая модель (LM) моделирует статистику языка. Он узнает, какие последовательности слов, скорее всего, будут произнесены, и его задача — предсказать, какие слова последуют за текущими словами и с какой вероятностью.
Хотя традиционный гибридный подход к распознаванию речи все еще широко используется, у него есть несколько недостатков. Более низкая точность, как обсуждалось ранее, является самой большой. Кроме того, каждую модель необходимо обучать независимо, что отнимает много времени и сил. Принудительно выровненные данные также трудно получить, и требуется значительное количество человеческого труда, что делает их менее доступными. Наконец, необходимы эксперты для создания пользовательского фонетического набора, чтобы повысить точность модели.
Комплексный подход к глубокому обучению
Сквозной подход к глубокому обучению — это новый взгляд на ASR.
С помощью сквозной системы вы можете напрямую преобразовать последовательность входных акустических характеристик в последовательность слов. Данные не нужно принудительно выравнивать. В зависимости от архитектуры систему глубокого обучения можно научить производить точные стенограммы без модели словаря и языковой модели, хотя языковые модели могут помочь получить более точные результаты.
Сквозные модели глубокого обучения легче обучать и они требуют меньше человеческого труда, чем традиционный подход. Они также более точны, чем традиционные модели, используемые сегодня.
Проблемы ASR сегодня
Одной из основных проблем ASR сегодня является постоянное стремление к уровню человеческой точности. Хотя оба подхода ASR — традиционный гибрид и сквозное глубокое обучение — значительно более точны, чем когда-либо прежде, ни один из них не может претендовать на 100% человеческую точность. Это потому, что в том, как мы говорим, так много нюансов, от диалектов до сленга и подачи. Даже лучшие модели глубокого обучения не могут быть обучены охватывать весь этот длинный хвост пограничных случаев без значительных усилий.
Еще одна важная проблема — конфиденциальность преобразования речи в текст для API . Слишком много крупных компаний ASR используют данные клиентов для обучения моделей без явного разрешения, что вызывает серьезные опасения по поводу конфиденциальности данных. Непрерывное хранение данных в облаке также вызывает опасения по поводу потенциальных нарушений безопасности, особенно если необработанные аудио- или видеофайлы или текст транскрипции содержат личную информацию.