
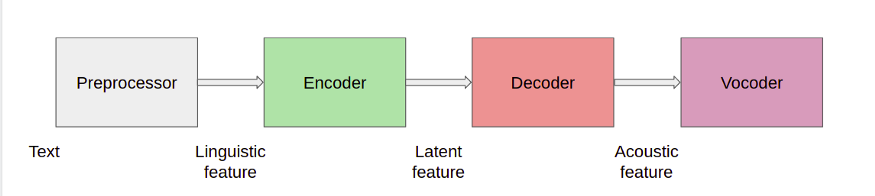
Это схема высокого уровня различных компонентов, используемых в системе TTS. Входными данными для нашей модели является текст, который проходит через несколько блоков и в конечном итоге преобразуется в звук. Давайте разберемся, что каждый из этих блоков вносит в процесс.
Препроцессор
Токенизация: предложение разбиваются на слова.
Фонемы/произношение: вводимый текст разбивается на фонемы в зависимости от их произношения. Например, «Hello, Have a good day» преобразуется в HH AH0 L OW1, HH AE1 V AH0 G UH1 DD EY1.
Продолжительность фонемы: представляет общее время, затрачиваемое каждой фонемой в аудио.
Высота тона: ключевая функция для передачи эмоций, она сильно влияет на просодию речи.
Энергия: указывает величину мел-спектрограмм на уровне кадра и напрямую влияет на громкость и просодию речи.
Лингвистическая функция содержит только фонемы. Энергия, высота тона и продолжительность фактически используются для обучения предсказателя энергии, предсказателя основного тона и предсказателя продолжительности соответственно, которые используются моделью для получения более естественного вывода.
Кодер
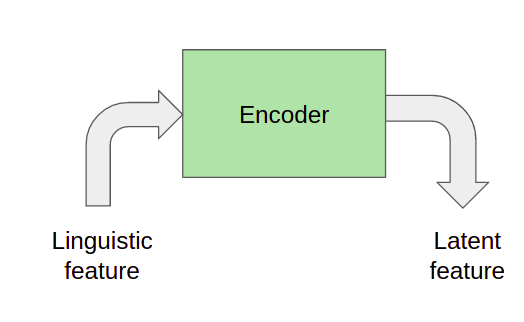
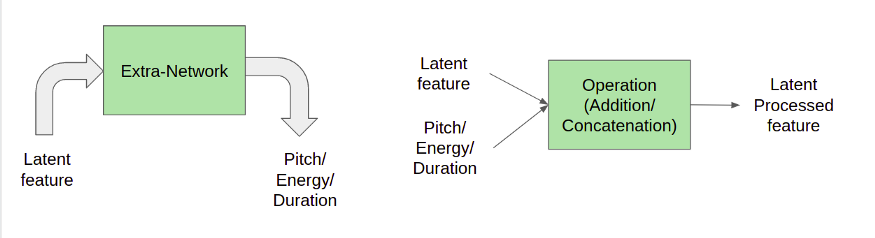
Кодер вводит лингвистические признаки (фонемы) и выводит n-мерное вложение. Это вложение между кодером и декодером известно как скрытая функция. Скрытые функции имеют решающее значение, потому что другие функции, такие как встраивание динамиков, объединяются с ними и передаются декодеру. Кроме того, скрытые функции также используются для прогнозирования энергии, высоты тона и продолжительности, которые, в свою очередь, играют решающую роль в управлении естественностью звука.
Декодер
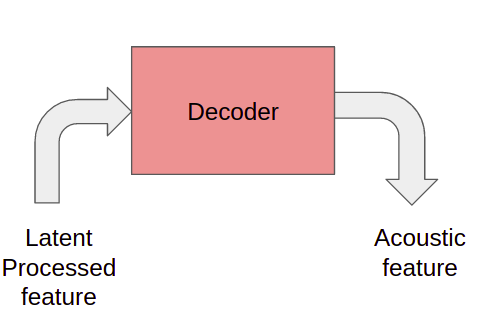
Декодер используется для преобразования информации, встроенной в латентный обработанный признак, в акустический признак, т.е. мел-спектрограмму.
Но зачем выводить мел-спектрограммы вместо того, чтобы напрямую воспроизводить речь/аудио из декодера?
Это связано с тем, что звук содержит больше информации о дисперсии (например, фазы), чем Mel-спектрограммы. Это вызывает больший информационный разрыв между входом и выходом для преобразования текста в аудио по сравнению с генерацией текста в спектрограмму. Следовательно, предпочтительно использовать Mel-спектрограммы.
Вокодер
Он преобразует акустическую характеристику (Mel-спектрограмму) в выходной сигнал (аудио). Это можно сделать с помощью математической модели, такой как Гриффин Лим, или мы также можем обучить нейронную сеть обучению отображению мел-спектрограммы в формы сигналов. На самом деле методы, основанные на обучении, обычно превосходят метод Гриффина Лима.
Таким образом, вместо прямого предсказания формы сигнала с помощью декодера, мы разделили эту сложную и изощренную задачу на два этапа: сначала предсказываем мел-спектрограмму из скрытых обработанных признаков, а затем генерируем звук с помощью мел-спектрограммы.
Супер!