The post Сбор текстовых данных для машинного обучения first appeared on Портал по разметке данных.
]]>Датасаентист Сбербанка рассказывает о сборе текстовых данных и построении корпусов. Корпус, с точки зрения машинного обучения, – это большой датасет. Это собранные тексты и некая разметка к ним. Хорошо подобранный корпус с достаточно низкой частотой слов способен решить большое количество проблем архитектуры.
Спикер делится своим опытом создания корпусов, рассказывает о закрытых и открытых источниках и как рассчитывать объём данных.
Источник: YouTube-канал ODS AI Global
The post Сбор текстовых данных для машинного обучения first appeared on Портал по разметке данных.
]]>The post Обработка текста. Решение задачи классификации first appeared on Портал по разметке данных.
]]>Видео состоит из лекции и семинара. Спикер рассказывает о том, что такое NLP, про обработку и текста и о том, какие задачи можно решить с помощью имеющихся данных.
Источник: YouTube-канал Deep Learning School
The post Обработка текста. Решение задачи классификации first appeared on Портал по разметке данных.
]]>The post Инструменты для разметки текста first appeared on Портал по разметке данных.
]]>1. labelstud.io
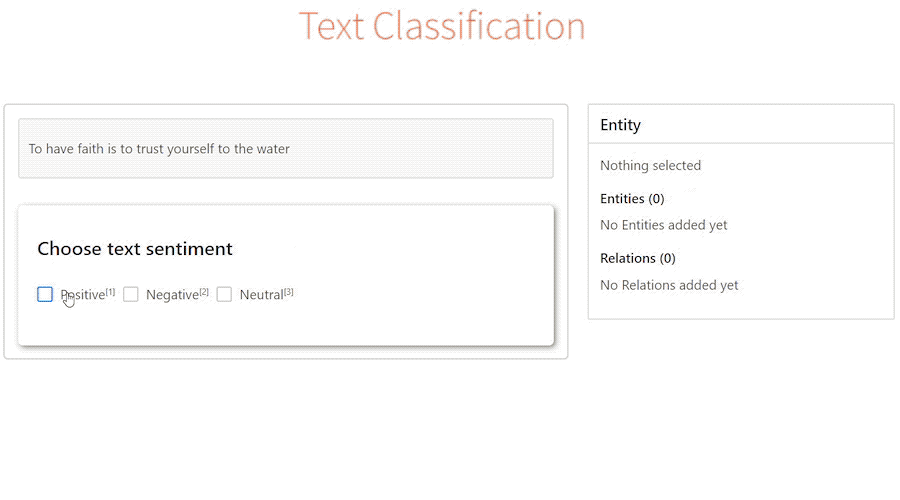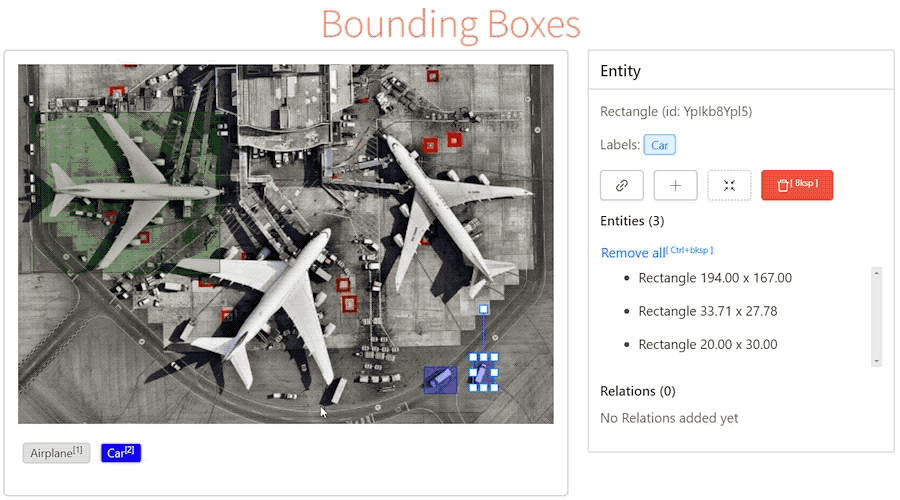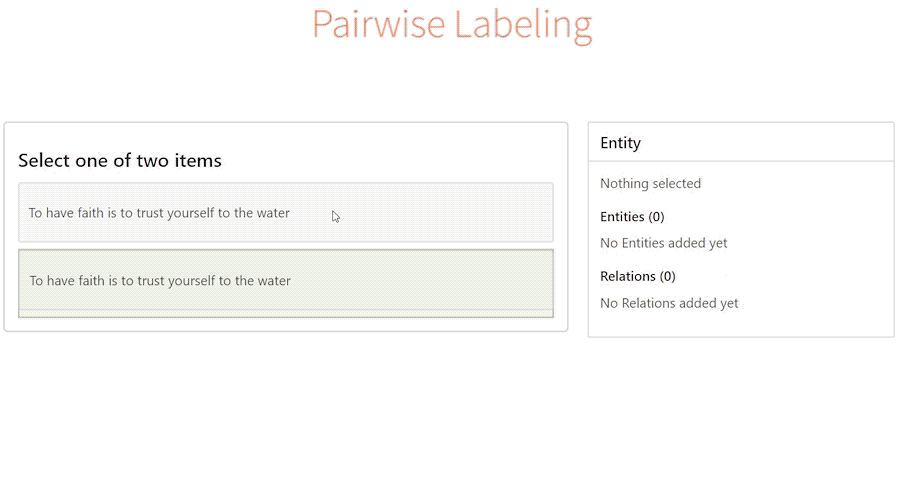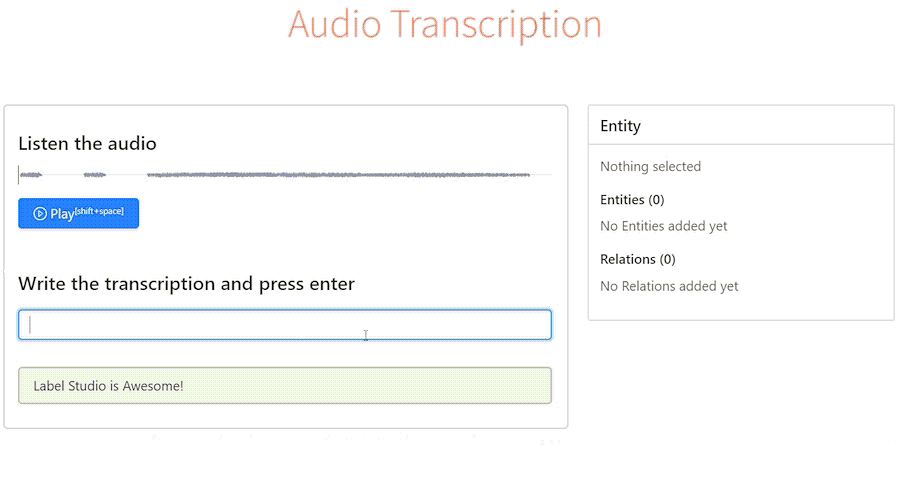
Начнем с его плюсов:
- Легко поднять и настроить. Ну то есть буквально две строчки в командной строке.
- Весь интерфейс достаточно интуитивный.
- Есть поддержка мультилейбла, иерархической классификации, relation extraction и прочих достаточно “экзотических” в NLP штук.
- Можно задавать свои шаблоны (templates) разметки если знаешь html.
- Можно запиливать свои модели, чтобы учились в режиме онлайн и делали pre-annotation + интеграции с различными БД.
- Кроме текста можно размечать и аудио.
- Есть open-source версия.
Минусы:
- Несмотря на интуитивность, в UI достаточно большое количество багов.
- Часть функционала отсутствует в бесплатной версии (об этом ниже).
- Достаточно дорогая платная версия.
В целом произвел впечатление добротного проекта на стадии поздней беты (в основном из-за интерфейса). Но при этом даже open-source версия поддерживает кучу полезных штук: пре-аннотации с моделями ML, интеграции с различными БД, кучу различных шаблонов и типов данных. Ну и сам факт, что ее можно быстро завести и настроить, уже говорит о многом.
Менеджмент проектов однако остается открытым вопросом – на мой взгляд, в бесплатной версии это сделано не очень удобно: ты создаешь проект и загружаешь туда диалоги, каждая реплика – отдельная задача (аннотация). В итоге придется под каждого разметчика (и под каждый пак данных!) создавать свой проект – это все будет разрастаться очень быстро и за этим придется активно следить. Менеджерить это все будет при небольшой команде (10 человек, +/-), наверное, не очень сложно, но если будете расти – придется думать, что с этим делать.
Не совсем понятно, насколько лучше ситуация в платной версии: не факт, что разделение админ/разметчик даст более прозрачную структуру проектов. Впрочем, у меня сложилось впечатление, что если эту самую структуру хорошо огранизовать и пару вечеров плотно покурить документацию с API – можно и на open-source версии жить очень долгое время.
Более подробно об отличиях платной и open-source версии можно почитать здесь. Основное отличие заключается в том, что у вас просто больше контроля над разметчиками: можно заводить задания под конкретных людей, иметь разделения на администратора/разметчика, подробные логи активности с аналитикой, автоматически производить кросс-валидацию и хостить сам сервис на серверах labelstudio.
Цены:
- Open-source – бесплатно.
- 300$ / пользователь / месяц (до 10 людей) за “team edition” которая лучше, чем open-source, но все равно имеет кучу ограничений, самое важное – нет разделения на разметчика/админа + нельзя заводить задания на конкретного пользователя. Какой-то сомнительный middle-ground, который, кажется, не стоит своих денег.
- Цена за enterprise не оглашается, но при большой команде это наверное единственный вариант, который, вероятнее всего, обойдется в копеечку.
2. tagtog.net
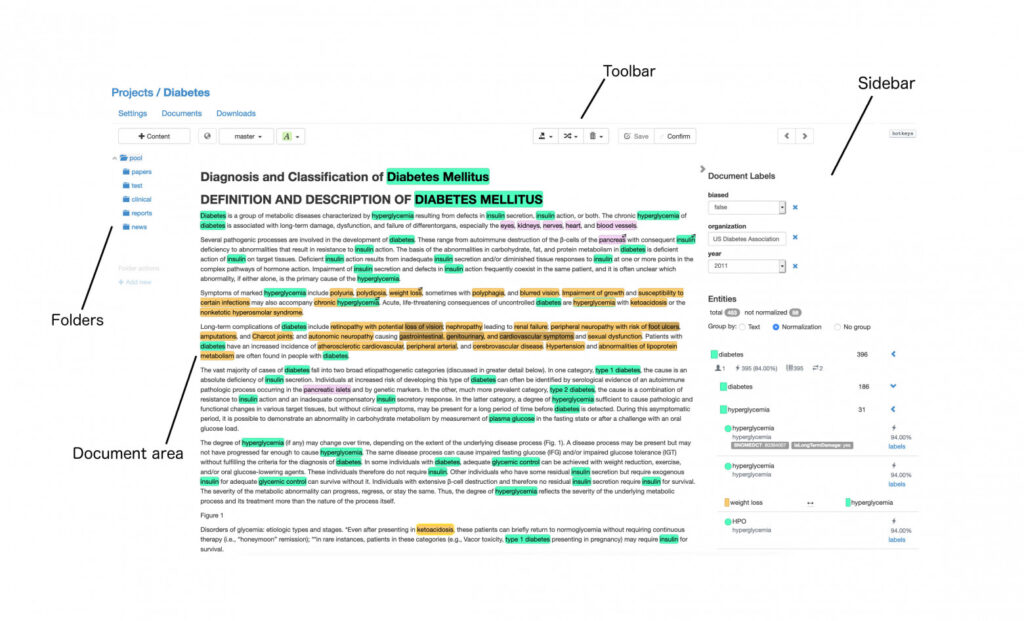
Из плюсов:
- Выглядит достаточно готовым продуктом, занимаются именно NLP (что, кстати, одновременно и минус, потому что в labelstudio, например, можно и аудио размечать, а нам это потенциально может быть очень кстати).
- Есть relation extraction и всякие другие полезные шаблоны.
- Есть open-source версия.
- Платная версия не очень дорогая.
- Можно впиливать свои модели, обученные на уже размеченных данных для пре-аннотаций того, что еще не разметили.
Из минусов:
- Загрузка файлов только через CLI, в интерфейсе такой возможности просто нет.
- Менеджмент проектов как в labelstudio, только с лишней головной болью насчет загрузки. Особенно печально если менеджерить это будет человек далекий от IT.
- UI на троечку (субъективно).
Работа по API, опять вопросы персональных данных, да и мне лично не очень комфортно когда ты чужой веб-сайт для таких вещей используешь, а не у себя что-то поднимаешь – просто гораздо меньше контроля над происходящим.
В целом выглядит так, что если вам не понравится open-source версия labelstudio – это второе, на что можно обратить внимание, если вы решите вопросы персональных данных.
С ценами можно ознакомиться здесь. Я бы не брал ничего ниже team pro (99$ / usr / month) т.к. пре-аннотации и разделение на разметчика / администратора – очень важные штуки, которые могут сэкономить вам в дальнейшем кучу времени и нервов.
3. prodi.gy – от создателей SpaCy
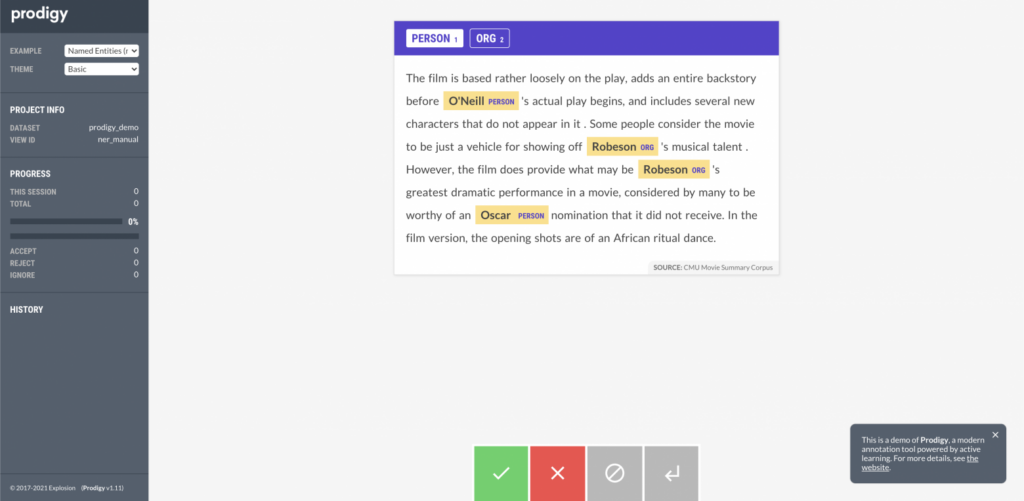
Плюсы:
- Недорогие (500$ / год).
- Есть демо версия (просто разметка) которую можно пощупать на сайте.
Минусы:
- Абсолютно упоротый CLI, который при достаточно большом шаблоне становится ну совсем неподъемным. Например, список лейблов нужно прописывать в консоли при создании проекта.
- Нет опенсорс версии чтобы пощупать, что к чему.
- Впиливать модели для пре-аннотаций можно только из SpaCy.
- Документация на троечку и не отвечает на многие вопросы.
- UI на троечку (опять же, очень субъективно).
- Про менеджмент проектов всего пару слов и выглядит так, как будто он не очень хорошо продуман.
В принципе, достаточно сказано. Выглядит, как очень узкоспециализированный инструмент для тех, кто плотно работает со SpaCy. Если это про вас, то больше информации можно найти на официальном сайте.
4. NLab Marker
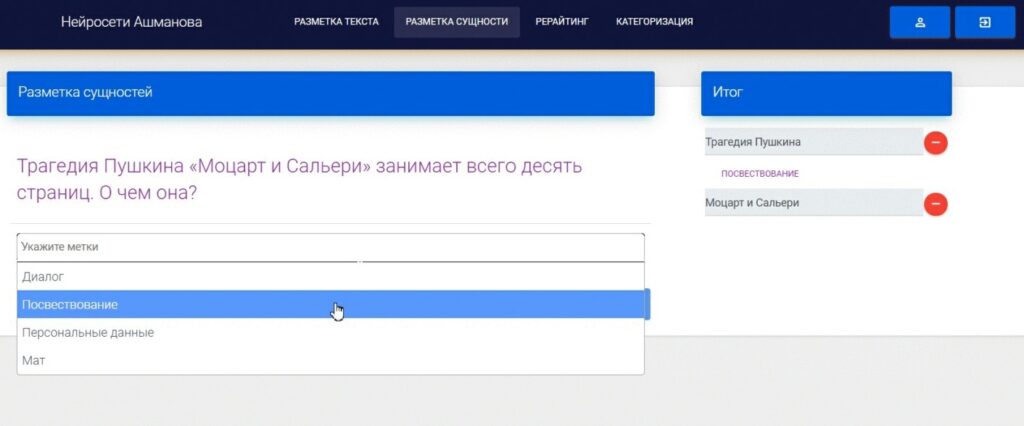
Это наш собственный маркер. Более подробно о нём можно почитать в нашей статье о маркере.
Статья написана на основании обзора на Habr.
The post Инструменты для разметки текста first appeared on Портал по разметке данных.
]]>The post Как анализировать текстовые данные? first appeared on Портал по разметке данных.
]]>В этой статье расскажем, что необходимо для создания инструмента анализа текста.
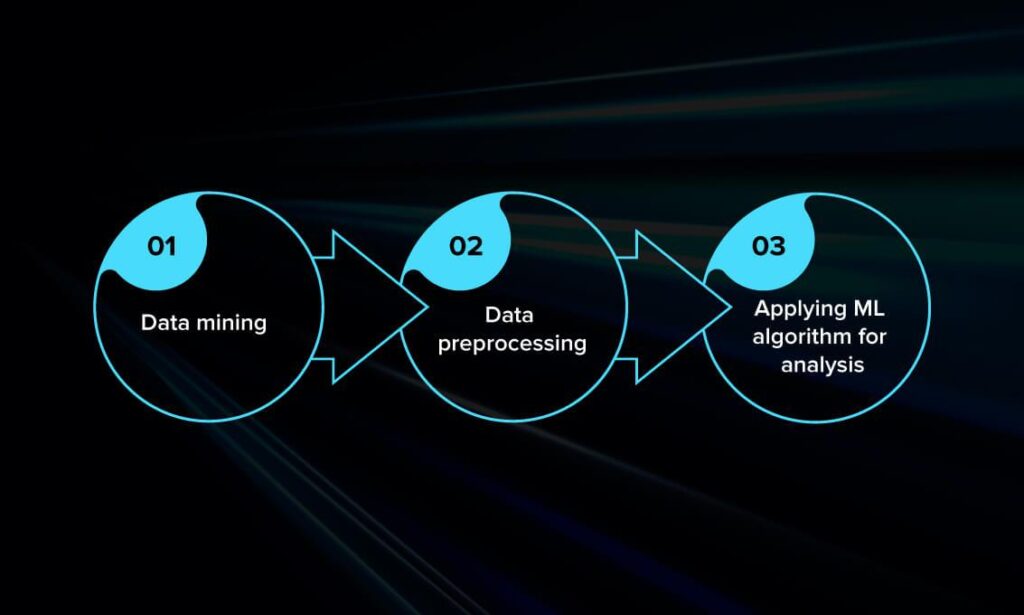
- Для начала нужно собрать данные. Существует два основных типа источников информации – внутренние и внешние данные. Внутренние данные генерируются каждый день из электронных писем и чатов, опросов клиентов и обращений в службу поддержки.Если вы заходите на такие ресурсы, как форумы или газеты, то вы собираете внешние данные.
- Далее необходимо подготовить данные. Неструктурированные данные должны быть подготовлены или предварительно обработаны. Иначе программа его не поймет.
- Наконец, примените алгоритм машинного обучения для анализа текста. Вы можете написать свой алгоритм с нуля или использовать библиотеку.
Какие методы машинного обучения используются для анализа текста?
Токенизация
Каждый токен представляет собой значимую единицу. Слова и знаки препинания являются токенами, а пробелы — нет.

Маркировка частями речи
Когда вы назначаете грамматическую категорию каждому токену, это тегирование части речи.

Лемматизация
Процесс удаления всех аффиксов (то есть суффиксов, префиксов и т. д.), прикрепленных к слову, чтобы сохранить его лексическую основу, также известную как корень, или его словарная форма, или лемма.
Стемминг
Удалив аффиксы из слова, вы получите основу, «чистую» форму слова. Google использует стемминг для индексации запросов. Вместо того, чтобы хранить все формы слова, лексикон сводится к основам. Процесс становится намного быстрее, но и менее точным, чем лемматизация.

Разбор
Существует два вида синтаксического анализа: зависимость и избирательный округ. Вы проводите разбор, когда хотите понять грамматическую структуру предложения.
Во время синтаксического анализа вы разбиваете текст на подфразы, также называемые составляющими. Это помогает представить структуру предложения. Недостаток: это контекстно-свободная грамматика. В предложении типа «Посещение родственников может быть скучно» алгоритм не смог бы понять двусмысленное значение. Тем не менее, это хорошо для проверки грамматики.

Анализ зависимостей идентифицирует основные слова в предложении и находит связанные слова, которые изменяют свое значение. Синтаксические отношения помогают понять, что означает предложение, особенно в синтетических языках , таких как славянские языки. Анализ зависимостей также применяется для проверки грамматики и обработки текстов, поскольку он может анализировать свободный порядок слов и фрагментированные предложения.

The post Как анализировать текстовые данные? first appeared on Портал по разметке данных.
]]>The post Методы анализа текста first appeared on Портал по разметке данных.
]]>- Классификация
Классификация текста — это процесс присвоения предопределенных тегов или категорий неструктурированному тексту. Он считается одним из самых полезных методов обработки естественного языка, потому что он настолько универсален и может организовывать, структурировать и классифицировать практически любую форму текста для предоставления значимых данных и решения проблем.

К наиболее распространенным задачам классификации текста можно отнести:
Анализ настроений (мнений)
Выявляет и изучает эмоции в тексте. Использует мощные алгоритмы машинного обучения для автоматического считывания и классификации по полярности мнений (положительные, отрицательные, нейтральные), по чувствам и эмоциям автора, даже по контексту и сарказму.
Тематический анализ
Классифицирует тексты по темам.
Обнаружение намерений
Используется для автоматического понимания причин обратной связи с клиентами. Это жалоба? Или клиент пишет с намерением приобрести продукт? Машинное обучение может читать разговоры чат-ботов или электронные письма и автоматически направлять их соответствующему отделу или сотруднику.
- Извлечение текста
Извлечение текста — еще один широко используемый метод анализа текста, который извлекает фрагменты данных, которые уже существуют в любом заданном тексте. Можно извлекать ключевые слова, цены, названия компаний, спецификации продуктов и т. д.
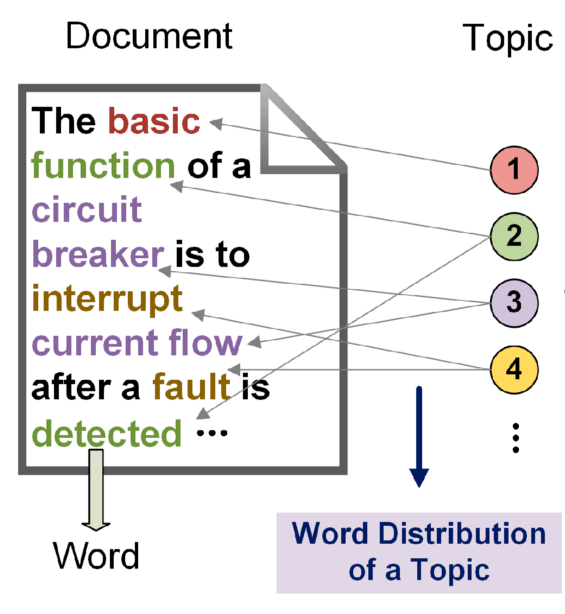
Извлечение ключевых слов
Ключевые слова — это наиболее часто используемые и наиболее релевантные термины в тексте, слова и фразы, обобщающие содержание текста.
Распознавание объектов
Сущности — это люди, компании или места, упомянутые в тексте.
- Частота слов
Метод анализа текста, который измеряет наиболее часто встречающиеся слова в тексте. Именно так можно определить тему текста и провести анализ настроений. Мы знаем, что слово «интересный» обычно относится к положительным впечатлениям. Так что если вы видите это слово в отзыве, значит, клиент доволен. Однако этот метод не чувствителен к сарказму, который может повлиять на общие результаты анализа.
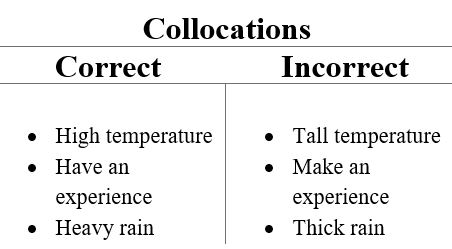
- Коллокация (словосочетание)
Словосочетаниями называются два, три и более слова, которые часто употребляются вместе в речи. Одно и то же слово в разных словосочетаниях может иметь разное значение.
Коллокация может быть полезна для выявления скрытых семантических структур и повышения детализации информации за счет подсчета биграмм и триграмм как одного слова.
- Анализ соответствия
Конкорданс — это таблица, которая отображает разные значения одного и того же слова в разных контекстах. Анализ соответствия и словосочетаний полезен для устранения неоднозначности значений ключевых слов.
- Кластеризация
Текстовые кластеры способны понимать и группировать огромное количество неструктурированных данных. Хотя они менее точны, чем алгоритмы классификации, алгоритмы кластеризации реализуются быстрее, поскольку для обучения моделей не нужно помечать примеры. Это означает, что эти интеллектуальные алгоритмы извлекают информацию и делают прогнозы без использования обучающих данных, иначе называемых неконтролируемым машинным обучением.
Google — отличный пример того, как работает кластеризация. Когда вы ищете термин в Google, задумывались ли вы когда-нибудь о том, что для получения релевантных результатов требуется всего несколько секунд? Алгоритм Google разбивает неструктурированные данные с веб-страниц и группирует страницы в кластеры вокруг набора похожих слов или n-грамм (всех возможных комбинаций соседних слов или букв в тексте). Таким образом, страницы из кластера, которые содержат большее количество слов или n-грамм, релевантных поисковому запросу, будут отображаться первыми в результатах.
The post Методы анализа текста first appeared on Портал по разметке данных.
]]>The post Что такое анализ текста в машинном обучении? first appeared on Портал по разметке данных.
]]>Анализ текста — это метод машинного обучения, используемый для извлечения ценной информации из неструктурированных текстовых данных. С помощью данного метода можно работать с различными типами текстовой информации, такие как публикации в социальных сетях, сообщения и электронные письма.
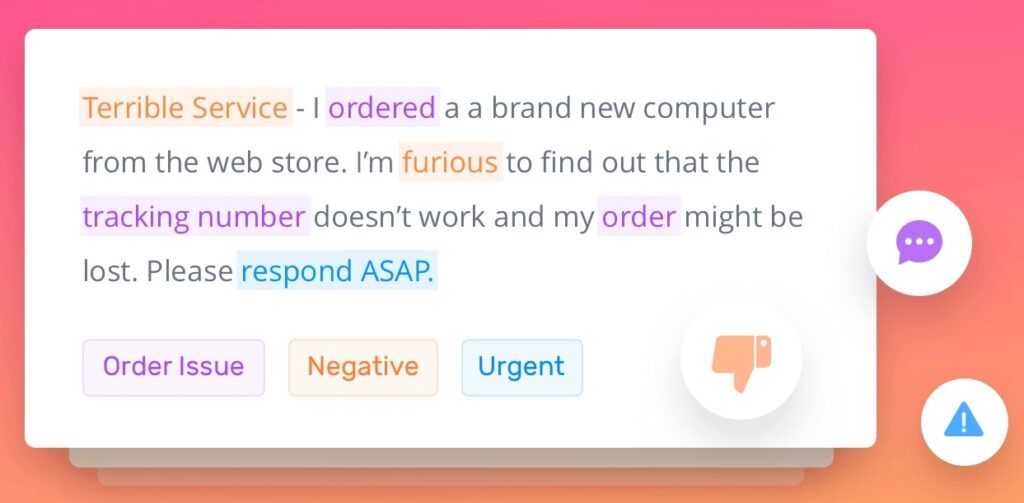
Иногда анализ текста путают с текстовой аналитикой. Однако, это два разных понятия. Они описывают один и тот же процесс, но всё же есть различия:
- Анализ текста работает со смыслом текста, то есть идентифицирует важную информацию в самом тексте. Например, этот процесс можно использовать, чтобы получить ответы на вопросы: отзыв положительный или отрицательный? Какова основная тема текста?
- Текстовая аналитика изучает закономерности в тысячах текстов. Результаты могут быть представлены на графиках, схемах и электронных таблицах. Если необходимо оценить процент положительных отзывов клиентов, то понадобится текстовая аналитика.
Зачем нужен анализ текста?
Машинное обучение делает анализ текста намного быстрее и эффективнее, чем ручная обработка. Это позволяет сократить трудозатраты и ускорить обработку текстов без ущерба для качества. С помощью текстового анализа компании структурируют огромное количество информации: электронные письма, чаты, социальные сети, запросы в службу поддержки, документы и т. д.
В итоге это дает возможность предоставить пользователям более качественные услуги. Также, изучая отзывы клиентов, компания может узнать общественное мнение о своей продукции.
Проблемы анализа текста
Текстовый анализ также представляет некоторые проблемы:
- Сложность. Преобразование текста в формат, который может быть обработан компьютером, требует нескольких шагов. Например, если мы решаем задачу классификации текста, нам нужно собрать данные, определить в них ключевые слова, определить ряд классов, сгруппировать данные по этим классам и описать эти процессы в математических терминах. Это сложно как интеллектуально, так и с точки зрения человеческих/денежных/временных ресурсов.
- Концептуальная борьба. Компьютеры не понимают понятий, стоящих за словами, поэтому им сложно работать с омографами. Программисты должны придумать несколько эффективных инструментов для устранения неоднозначности значений слов, чтобы работать с такими предложениями, как «Will, will Will, Will Will’s will?». Google Translate, например, сейчас не справляется с этим предложением.
- Понимание культуры. Понимание человеческой речи означает понимание их эмоций. Одной из самых сложных эмоций для компьютера является сарказм. Продолжая тему устранения неоднозначности, одно и то же значение в разных культурах может быть выражено разными словами, такими как сленг или местные варианты. Что для британца «джемпер», для американца — «свитер». Компьютерная программа должна иметь опыт и культурный опыт, чтобы эффективно общаться с говорящими, которые используют менее традиционные формы языка.
Заключение
Анализ текста — это технология, которая используется в различных отраслях от маркетинга и продаж до робототехники. Специальные модели помогают научить машину работать с такими данными и делать из них ценные выводы. В целом, это может быть ценным методом для получения информации о вашем продукте или вашем бизнесе.
The post Что такое анализ текста в машинном обучении? first appeared on Портал по разметке данных.
]]>The post Кластеризация коротких текстов first appeared on Портал по разметке данных.
]]>На этом видео спикер рассказывает, как сделать кластеризацию коротких текстов, состоящих из одного или нескольких предложений.
Источник: YouTube-канал ODS AI Ru
The post Кластеризация коротких текстов first appeared on Портал по разметке данных.
]]>