The post Одноголосный синтез речи на основе нейронных сетей first appeared on Портал по разметке данных.
]]>На видео разбирают простую задачу: есть набор из текстов и соответствующих аудио. Необходимо натренировать нейронную сеть, чтобы она, получая текст на входе, выдавала результат в виде аудио. На основе примера спикер подробно рассказывает о пайплайнах для решения этой задачи, о разных аудиофичах, про метрики этой задачи и про архитектуры сетей.
Источник: YouTube-канал ODS AI Ru
The post Одноголосный синтез речи на основе нейронных сетей first appeared on Портал по разметке данных.
]]>The post Попробуйте наш продукт по синтезу речи first appeared on Портал по разметке данных.
]]>Мы в «Наносемантике» имеем большой опыт в разработке голосовых помощников, поэтому решили разобраться в перспективном направлении TTS и создали свою технологию синтеза речи NLab Speech TTS на русском языке.
Синтез речи работает на разных цифровых устройствах: компьютеры, смартфоны, планшеты. Все, что для него нужно, — это текст, который требуется воспроизвести. Если простыми словами, то синтез речи — это формирование речевого сигнала по печатному тексту, то есть искусственное производство речи человека.
Как работает NLab Speech TTS
Для разработки и запуска технологии синтеза речи мы обучили несколько голосовых моделей, используя для этого нейронные сети.
Поэтапный процесс синтеза речи:
- Сначала nlp-препроцессор отвечает за подготовку данных и используется в ситуациях когда, например, необходимо расставить ударения, «е/ё» и так далее. Этот процесс осуществляется автоматически с помощью словарей и нейронных сетей;
- Движок переводит текст в мелспектограммы;
- Вокодер переводит мелспектограммы в голос (для каждого диктора обучается обучается своя модель);
- Постобработка — корректируется скорость, тон и громкость синтезируемого аудио.
Особенности NLab Speech TTS





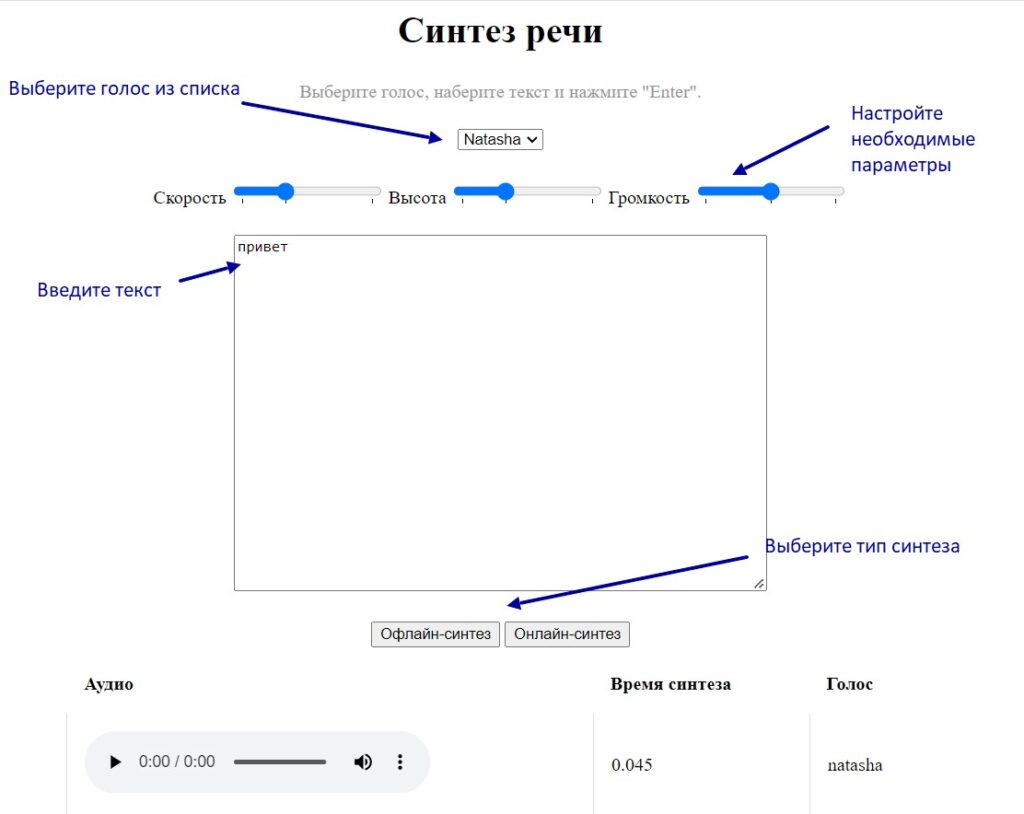
Проверьте, как это работает в демо-версии
Протестировать наш продукт можно по этой ссылке
The post Попробуйте наш продукт по синтезу речи first appeared on Портал по разметке данных.
]]>The post Набор данных для перевода речи first appeared on Портал по разметке данных.
]]>Общедоступный многоязычный корпус для перевода речи. Он охватывает восемь языковых направлений, от английского до немецкого, испанского, французского, итальянского, голландского, португальского, румынского и русского. Корпус состоит из аудиозаписей, транскрипций и переводов выступлений TED на английском языке, а также включает в себя предопределенные разделы для обучения, проверки и тестирования.
Получить более подробную информацию о проекте, а также скачать набор данных можно по ссылке.
The post Набор данных для перевода речи first appeared on Портал по разметке данных.
]]>The post Структура преобразования текста в речь (TTS) first appeared on Портал по разметке данных.
]]>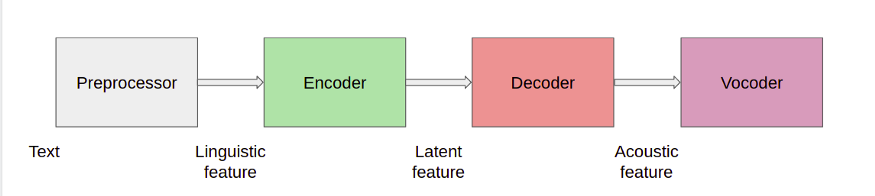
Это схема высокого уровня различных компонентов, используемых в системе TTS. Входными данными для нашей модели является текст, который проходит через несколько блоков и в конечном итоге преобразуется в звук. Давайте разберемся, что каждый из этих блоков вносит в процесс.
Препроцессор
Токенизация: предложение разбиваются на слова.
Фонемы/произношение: вводимый текст разбивается на фонемы в зависимости от их произношения. Например, «Hello, Have a good day» преобразуется в HH AH0 L OW1, HH AE1 V AH0 G UH1 DD EY1.
Продолжительность фонемы: представляет общее время, затрачиваемое каждой фонемой в аудио.
Высота тона: ключевая функция для передачи эмоций, она сильно влияет на просодию речи.
Энергия: указывает величину мел-спектрограмм на уровне кадра и напрямую влияет на громкость и просодию речи.
Лингвистическая функция содержит только фонемы. Энергия, высота тона и продолжительность фактически используются для обучения предсказателя энергии, предсказателя основного тона и предсказателя продолжительности соответственно, которые используются моделью для получения более естественного вывода.
Кодер
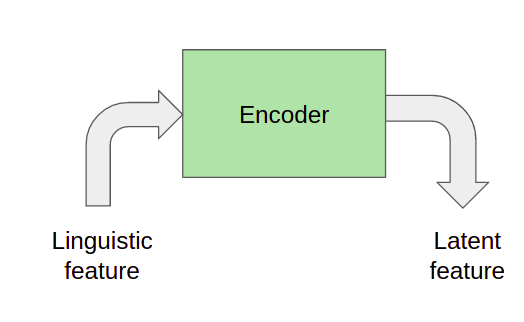
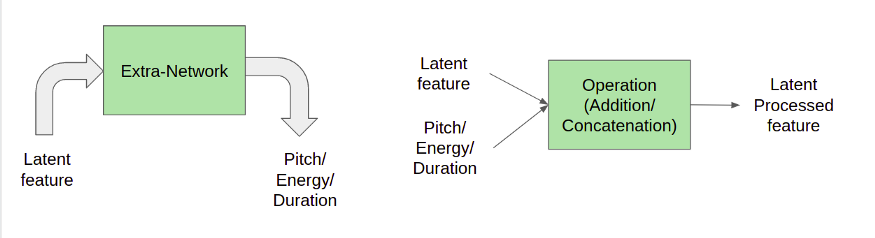
Кодер вводит лингвистические признаки (фонемы) и выводит n-мерное вложение. Это вложение между кодером и декодером известно как скрытая функция. Скрытые функции имеют решающее значение, потому что другие функции, такие как встраивание динамиков, объединяются с ними и передаются декодеру. Кроме того, скрытые функции также используются для прогнозирования энергии, высоты тона и продолжительности, которые, в свою очередь, играют решающую роль в управлении естественностью звука.
Декодер
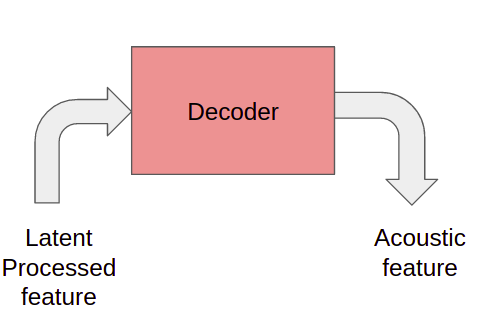
Декодер используется для преобразования информации, встроенной в латентный обработанный признак, в акустический признак, т.е. мел-спектрограмму.
Но зачем выводить мел-спектрограммы вместо того, чтобы напрямую воспроизводить речь/аудио из декодера?
Это связано с тем, что звук содержит больше информации о дисперсии (например, фазы), чем Mel-спектрограммы. Это вызывает больший информационный разрыв между входом и выходом для преобразования текста в аудио по сравнению с генерацией текста в спектрограмму. Следовательно, предпочтительно использовать Mel-спектрограммы.
Вокодер
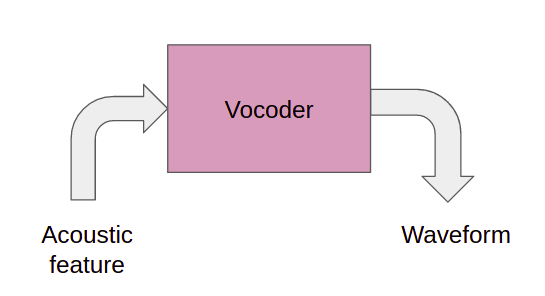
Он преобразует акустическую характеристику (Mel-спектрограмму) в выходной сигнал (аудио). Это можно сделать с помощью математической модели, такой как Гриффин Лим, или мы также можем обучить нейронную сеть обучению отображению мел-спектрограммы в формы сигналов. На самом деле методы, основанные на обучении, обычно превосходят метод Гриффина Лима.
Таким образом, вместо прямого предсказания формы сигнала с помощью декодера, мы разделили эту сложную и изощренную задачу на два этапа: сначала предсказываем мел-спектрограмму из скрытых обработанных признаков, а затем генерируем звук с помощью мел-спектрограммы.
The post Структура преобразования текста в речь (TTS) first appeared on Портал по разметке данных.
]]>The post Что такое преобразование текста в речь (TTS) first appeared on Портал по разметке данных.
]]>TTS — это компьютерное моделирование человеческой речи из текстового представления с использованием методов машинного обучения. Обычно синтез речи используется разработчиками для создания голосовых роботов, таких как IVR (Interactive Voice Response).
TTS экономит время и деньги бизнеса, поскольку автоматически генерирует звук, тем самым избавляя компанию от необходимости вручную записывать (и перезаписывать) аудиофайлы.
Вы можете прочитать любой текст вслух голосом, максимально приближенным к естественному, благодаря синтезу TTS. Чтобы синтезированная речь TTS звучала естественно, кропотливый процесс оттачивания ее тембра, плавности, расстановки акцентов и пауз, интонации и других направлений является длительным и неизбежным бременем.
Разработчики могут сделать это двумя способами:
Конкатенативный – склеивание фрагментов записанного звука. Эта синтезированная речь имеет высокое качество, но требует много данных для машинного обучения.
Параметрический — построение вероятностной модели, подбирающей акустические свойства звукового сигнала для заданного текста. Используя этот подход, можно синтезировать речь, практически неотличимую от реальной человеческой.
Чтобы преобразовать текст в речь, система ML должна выполнить следующее:
Преобразование текста в слова
Во-первых, алгоритм ML должен преобразовывать текст в удобочитаемый формат. Сложность здесь в том, что текст содержит не только слова, но и цифры, сокращения, даты и т. д.
Они должны быть переведены и написаны словами. Затем алгоритм делит текст на отдельные фразы, которые затем система читает с соответствующей интонацией. При этом программа следит за пунктуацией и устойчивыми структурами в тексте.
Полная фонетическая транскрипция
Каждое предложение может произноситься по-разному в зависимости от смысла и эмоционального тона. Для понимания правильного произношения система использует встроенные словари.
Если требуемое слово отсутствует, алгоритм создает транскрипцию по общим академическим правилам. Алгоритм также проверяет записи говорящих и определяет, на какие части слов они делают акцент.
Затем система подсчитывает, сколько 25-миллисекундных фрагментов содержится в скомпилированной транскрипции. Это известно как обработка фонем.
Фонема – это минимальная единица звуковой структуры языка.
Система описывает каждое произведение по разным параметрам: частью какой фонемы оно является, какое место в ней занимает, какому слогу принадлежит эта фонема и т.д. После этого система воссоздает соответствующую интонацию, используя данные фраз и предложений.
Преобразование транскрипции в речь
Наконец, система использует акустическую модель для чтения обработанного текста. Алгоритм ML устанавливает связь между фонемами и звуками, придавая им точную интонацию.
Система использует генератор звуковых волн для создания вокального звука. Частотные характеристики фраз, полученные из акустической модели, в итоге загружаются в генератор звуковых волн.
Отраслевые приложения TTS
Голосовые уведомления и напоминания. Это позволяет доставлять любую информацию вашим клиентам по всему миру с помощью телефонного звонка. Хорошей новостью является то, что сообщения доставляются на родных языках клиентов.
Прослушивание письменного содержания. Вы можете услышать синтезированный голос, читающий вашу любимую книгу, электронную почту или содержимое веб-сайта. Это очень важно для людей с ограниченными способностями к чтению и письму или для тех, кто предпочитает слушать чтение.
Локализация. Если вы работаете на международном уровне, наем сотрудников, говорящих на нескольких языках клиентов, может оказаться дорогостоящим. TTS позволяет практически мгновенно озвучивать английский (или другие языки) на любой иностранный язык. Это при условии, что вы пользуетесь надлежащей службой перевода.
The post Что такое преобразование текста в речь (TTS) first appeared on Портал по разметке данных.
]]>The post Набор данных русской речи по мобильному телефону first appeared on Портал по разметке данных.
]]>Набор содержит 200 000 часов данных распознавания речи, записанных с помощью различного профессионального оборудования, охватывающих самые разные сцены. В записи с аутентичным акцентом участвовало 1960 носителей русского языка. Записанный сценарий разработан лингвистами и охватывает широкий спектр тем, включая общие, интерактивные, автомобильные и домашние. Текст вычитывается вручную с высокой точностью.
Получить более подробную информацию о проекте, а также скачать набор данных можно по ссылке.
The post Набор данных русской речи по мобильному телефону first appeared on Портал по разметке данных.
]]>The post Видеолекция. Введение в распознавание речи first appeared on Портал по разметке данных.
]]>На этом видео спикер рассказывает о том, как можно решать более сложные и интересные задачи распознавания речи.
Источник: YouTube-канал Deep Learning School
The post Видеолекция. Введение в распознавание речи first appeared on Портал по разметке данных.
]]>The post Что такое автоматическое распознавание речи first appeared on Портал по разметке данных.
]]>Автоматическое распознавание речи, или ASR, — это использование технологии машинного обучения или искусственного интеллекта (ИИ) для преобразования человеческой речи в читаемый текст. За последнее десятилетие эта область значительно расширилась: системы ASR появились в популярных приложениях, которые мы используем каждый день.
Основные области применения ASR
Огромные достижения в области ASR привели к корреляции с ростом API-интерфейсов преобразования речи в текст. Компании используют технологию ASR для приложений преобразования речи в текст в самых разных отраслях. Вот некоторые примеры:
Телефония. Отслеживание вызовов, решения для облачных телефонов и контакт-центры нуждаются в точных транскрипциях, а также в инновационных аналитических функциях, таких как Conversational Intelligence, аналитика вызовов, диаризация говорящих и многое другое.
Платформы для видео: субтитры в режиме реального времени и асинхронные видео являются отраслевым стандартом. Платформы (как и видеоредакторы ) также нуждаются в категоризации контента и модерации контента для улучшения доступности и поиска.
Медиа-мониторинг: API-интерфейсы преобразования речи в текст могут помочь телетрансляциям, подкастам, радио, а также более быстро и точно обнаруживать упоминания брендов и других тем для повышения качества рекламы.
Виртуальные встречи. Платформы для встреч, такие как Zoom, Google Meet, WebEx и другие, нуждаются в точных расшифровках и возможности анализировать этот контент, чтобы получать ключевые идеи и действовать.
Как работает ASR
На сегодняшний день существует два основных подхода к автоматическому распознаванию речи: традиционный гибридный подход и сквозной подход к глубокому обучению.
Традиционный гибридный подход
Традиционный гибридный подход является устаревшим подходом к распознаванию речи и доминировал в этой области в течение последних пятнадцати лет. Многие компании до сих пор полагаются на этот традиционный гибридный подход просто потому, что так всегда делалось — существует больше знаний о том, как построить надежную модель, благодаря обширным доступным данным исследований и обучения, несмотря на плато в точности.
Традиционные системы HMM (скрытые марковские модели) и GMM (модели гауссовых смесей) требуют принудительного выравнивания данных. Принудительное выравнивание — это процесс получения текстовой транскрипции звукового речевого сегмента и определения того, где во времени встречаются определенные слова в речевом сегменте.
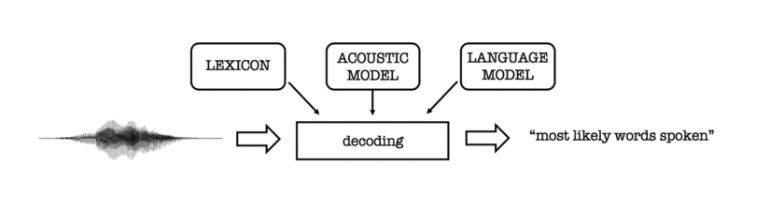
Как вы можете видеть на приведенной выше иллюстрации, этот подход сочетает в себе лексическую модель + акустическую модель + языковую модель для прогнозирования транскрипции.
Модель лексики описывает, как слова произносятся фонетически. Обычно вам нужен собственный набор фонем для каждого языка, созданный опытными фонетиками вручную.
Акустическая модель (АМ) моделирует акустические паттерны речи. Задача акустической модели состоит в том, чтобы предсказать, какой звук или фонема произносится в каждом сегменте речи, на основе принудительно выровненных данных. Акустическая модель обычно представляет собой вариант HMM или GMM.
Языковая модель (LM) моделирует статистику языка. Он узнает, какие последовательности слов, скорее всего, будут произнесены, и его задача — предсказать, какие слова последуют за текущими словами и с какой вероятностью.
Хотя традиционный гибридный подход к распознаванию речи все еще широко используется, у него есть несколько недостатков. Более низкая точность, как обсуждалось ранее, является самой большой. Кроме того, каждую модель необходимо обучать независимо, что отнимает много времени и сил. Принудительно выровненные данные также трудно получить, и требуется значительное количество человеческого труда, что делает их менее доступными. Наконец, необходимы эксперты для создания пользовательского фонетического набора, чтобы повысить точность модели.
Комплексный подход к глубокому обучению
Сквозной подход к глубокому обучению — это новый взгляд на ASR.
С помощью сквозной системы вы можете напрямую преобразовать последовательность входных акустических характеристик в последовательность слов. Данные не нужно принудительно выравнивать. В зависимости от архитектуры систему глубокого обучения можно научить производить точные стенограммы без модели словаря и языковой модели, хотя языковые модели могут помочь получить более точные результаты.
Сквозные модели глубокого обучения легче обучать и они требуют меньше человеческого труда, чем традиционный подход. Они также более точны, чем традиционные модели, используемые сегодня.
Проблемы ASR сегодня
Одной из основных проблем ASR сегодня является постоянное стремление к уровню человеческой точности. Хотя оба подхода ASR — традиционный гибрид и сквозное глубокое обучение — значительно более точны, чем когда-либо прежде, ни один из них не может претендовать на 100% человеческую точность. Это потому, что в том, как мы говорим, так много нюансов, от диалектов до сленга и подачи. Даже лучшие модели глубокого обучения не могут быть обучены охватывать весь этот длинный хвост пограничных случаев без значительных усилий.
Еще одна важная проблема — конфиденциальность преобразования речи в текст для API . Слишком много крупных компаний ASR используют данные клиентов для обучения моделей без явного разрешения, что вызывает серьезные опасения по поводу конфиденциальности данных. Непрерывное хранение данных в облаке также вызывает опасения по поводу потенциальных нарушений безопасности, особенно если необработанные аудио- или видеофайлы или текст транскрипции содержат личную информацию.
The post Что такое автоматическое распознавание речи first appeared on Портал по разметке данных.
]]>The post Набор записей звуков людей (смех, кашель и пр.) first appeared on Портал по разметке данных.
]]>Бесплатный набор данных, состоящий из 21 024 собранных на основе краудсорсинга записей смеха, вздохов, кашля, откашливания, чихания и фырканья от 3365 уникальных субъектов. Набор данных также содержит метаданные, такие как возраст говорящего, пол, родной язык, страна и состояние здоровья.
Получить более подробную информацию о проекте, а также скачать набор данных можно по ссылке.
The post Набор записей звуков людей (смех, кашель и пр.) first appeared on Портал по разметке данных.
]]>The post Видеолекция. Введение в обработку звука first appeared on Портал по разметке данных.
]]>На этом видео спикер рассказывает о том, как хранятся аудиофайлы и что они из себя представляют, как удобно представлять звуковую информацию перед тем, как передавать её в нейронную сеть.
Источник: YouTube-канал Deep Learning School
The post Видеолекция. Введение в обработку звука first appeared on Портал по разметке данных.
]]>